Table of Contents
Introduction
My husband and I have recently been considering starting a family together (i.e., having children). Naturally, wanting to give my children the best chance at a healthy, successful life, I spent some time over the past several weeks personally surveying the landscape of embryo selection companies. These companies essentially facilitate in vitro fertilization by using polygenic scores to help you select the ‘best’ embryo.
This post isn’t meant as an introduction to the field of polygenic testing; for those who want a broader overview, Scott Alexander’s recent post recent post is an excellent primer which compares the current players in the field. Instead, the purpose of this post is simple: as I started learning more about Nucleus Genomics and researching their newly launched product, Nucleus Origin, I noticed a number of increasingly bizarre inconsistencies and errors in their promotional content. In addition, I also noticed that they are apparently currently being sued by a competitor, Genomic Prediction, for what appears to be egregious IP theft.
Upon further exploration, I realized that their entire Nucleus Origin whitepaper, touted as a novel AI breakthrough in the field of “genetic optimization,” was essentially full of basic errors that were so flagrant that a dilettante in the field like myself was able to spot them with a cursory review. Worse, the entire whitepaper appears to have been cribbed wholesale from a competitor’s medRxiv preprint.
After conducting more background research, I concluded that Nucleus Origin was essentially meant as a response to a competitor’s whitepaper claiming to show that Nucleus systematically misrepresents the predictive validity of their polygenic scores (PGS). The claims in that whitepaper, if true, are fairly damning and, even after the release of the Nucleus Origin whitepaper, largely go unaddressed. I strongly recommend that any reader curious to learn more about Nucleus also spend some time closely reading the linked critique.
In this article, I begin by documenting a series of bizarre and misleading claims made by Nucleus in their marketing material. It was these discrepancies which led me “down the rabbit hole,” so to speak, and prompted me to examine the technical claims made by Nucleus in closer detail. Afterward, I discuss the allegations made about borderline fraudulent misrepresentation of their polygenic scores and their obvious plagiarism of a Herasight whitepaper for their own product.
Having children is one of the most consequential decisions that a family can make. It obviously follows that if you’re choosing a company to help you through the IVF and embryo selection process, you should probably care about the quality and integrity of that company’s work. I would recommend any prospective parent considering Nucleus as a service provider to carefully examine the claims made in this article and come to their own conclusions.
Down the rabbit hole
Nucleus Genomics is a genetic testing company that’s been around since at least 2021. Earlier this year, they launched a carrier screening product and shortly afterward a polygenic embryo screening product through a partnership with Genomic Prediction (the same company now suing them for IP theft). They claim to “screen for 2000 conditions”, which seem to mostly constitute single-gene disorders along with a few dozen polygenic traits.
Their website is sleek, with testimonials from satisfied customers plastered all over each product page. So far, so good, right? However, upon closer inspection, there are a number of obvious inconsistencies. The degree and severity of some of these inconsistencies are great enough that they really make one wonder about whether there are any legitimate reviews on the website at all.
Potentially fictitious customer reviews
One simple example:

It is chronologically impossible for these reviews to be true because Nucleus started offering carrier screening in the spring of 2025 and their IVF product in May 2025. It is currently November 2025, meaning that no couple could have even gone through carrier screening and IVF with Nucleus and had a successful conception at the time of writing, let alone produce a child mature enough to walk or grow a full head of hair.
I will admit that it’s theoretically possible that Nucleus started offering their carrier screening to individuals well before the official launch of their services. However, given that the picture of the family in the middle is cribbed from a random AgelessRX article, and the woman on the left from stock photography titled Mother Carrying Her Baby, I think the more likely possibility is that these reviews are total fabrications.
Or perhaps compare these two testimonials:
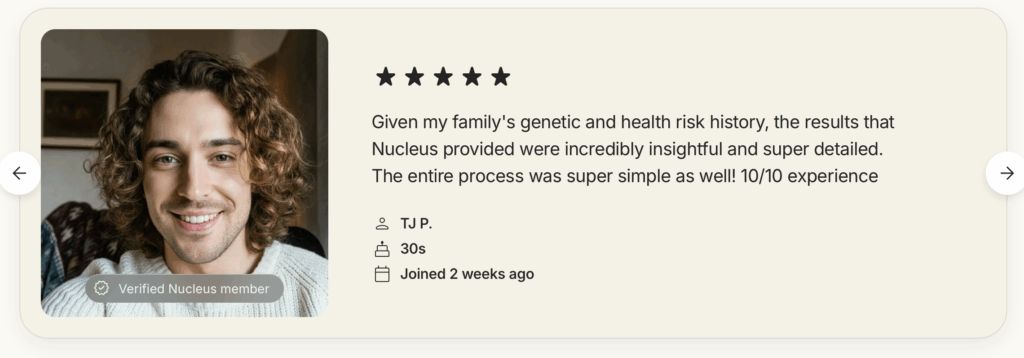
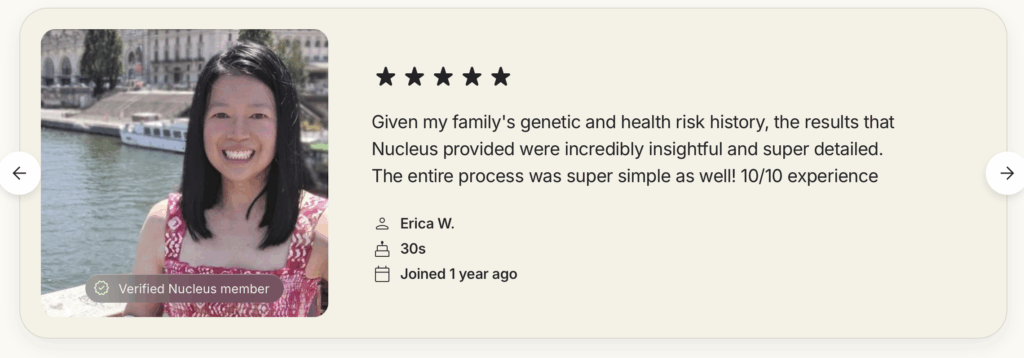
Wow, these two Verified Nucleus Members sure have very similar writing styles! In the process of writing this article, I took multiple screenshots of these testimonials, and it’s interesting that 3 weeks ago, “TJ P.” was also listed as having joined 2 weeks ago. Also, he appears to have recently changed his name:
What about the handsome Yasir A.?
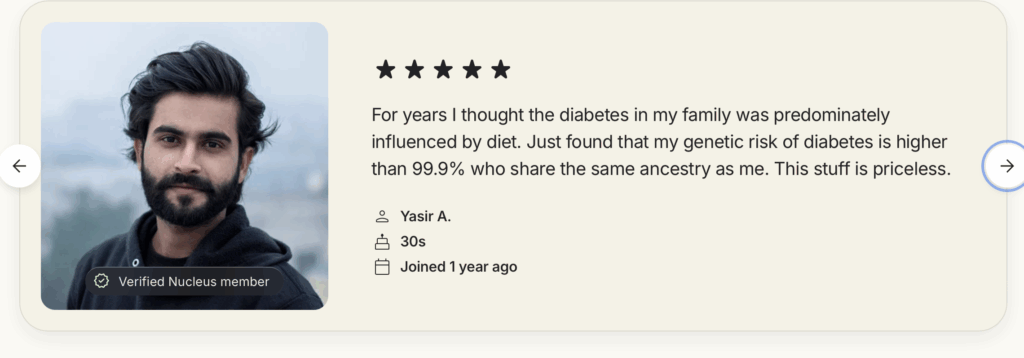
It’s not surprising that with such striking facial features, he also seems to moonlight as a model for stock photographers and of course no wonder that Nucleus chose to prominently display the well known masterpiece of stock photography, “man in black zip up jacket” (“photography in Noida, India by Naim Ahmed”). What a cosmopolitan business!
In fact, in between the time I began writing this post and the time of posting, Yasir seems to also have undergone a remarkable racial transmogrification despite his result being calibrated to those “who share the same ancestry as me”:

These are arguably all relatively minor misrepresentations in the grand scheme of things; however, there is one particularly egregious and potentially even dangerous case here, namely that of Jeffrey B.:

The X.com link does not work and the profile photo is obviously AI-generated:

It’s difficult to know for sure, but I think this review actually comes from a paid reviewer who is actually named Jeffrey B., in reality a pasty white European-American. Attaching a Black man’s picture to his review is especially misleading due to ancestry mismatch, because Nucleus “modulate[s] the polygenic score’s estimated predictive power according to the genetic distance of the user’s ancestry from the ancestry of the training population to ensure non-European populations can still receive rigorous, meaningful genetic analysis results today”. The real Jeffrey B. later posted that his results were informative with respect to his unexpectedly high predicted Alzheimer’s risk of 70% and, despite his family history, low predicted risk of coronary artery disease (CAD).
The reason this is an issue is because it’s well known that the ethnic portability of polygenic scores (i.e. how well a PGS works in a different population than the one it was trained on) varies depending on the degree of mismatch between these two populations, something that has to be taken into account when reporting results. Therefore, it wouldn’t be the case that Jeffrey’s supposedly informative predicted CAD risk would also apply to the advertised Jeffrey B., who appears to be an AI-generated black man (similarly, given that Yasir A.’s reviews above show mismatched stock and AI-generated photos, I imagine the same issue applies to a lesser degree to him as well). Oh, and given that Nucleus’ CAD PGS seems to be severely miscalibrated compared to a third party validation (more on this later), their results for the true Jeffrey B. are also almost certainly miscalibrated.
I understand that marketing is important, and I’m not lambasting Nucleus for spending effort on promoting their product. However, as I mentioned above, choosing a provider for embryo selection entails choosing a company with which you’ll form a relationship of deep trust. It’s difficult to imagine how I could in good conscience choose Nucleus to select the embryo who will be my future child when they distort facts as basic as the racial transferability of their results in service of getting customers.
Obviously AI-generated blog posts
There isn’t anything intrinsically wrong with using AI to write blog posts, and evaluations of writing style remain matters of taste. However, it does seem concerning when most, if not all, posts are completely drafted by AI and posted without any manual review (just take a look here).
How do I know that this happened? Well, before they started offering their IVF product, they published a review of Orchid Health, a competitor which also offers polygenic embryo screening, where Nucleus actually includes a theoretical critique of polygenic risk scores:
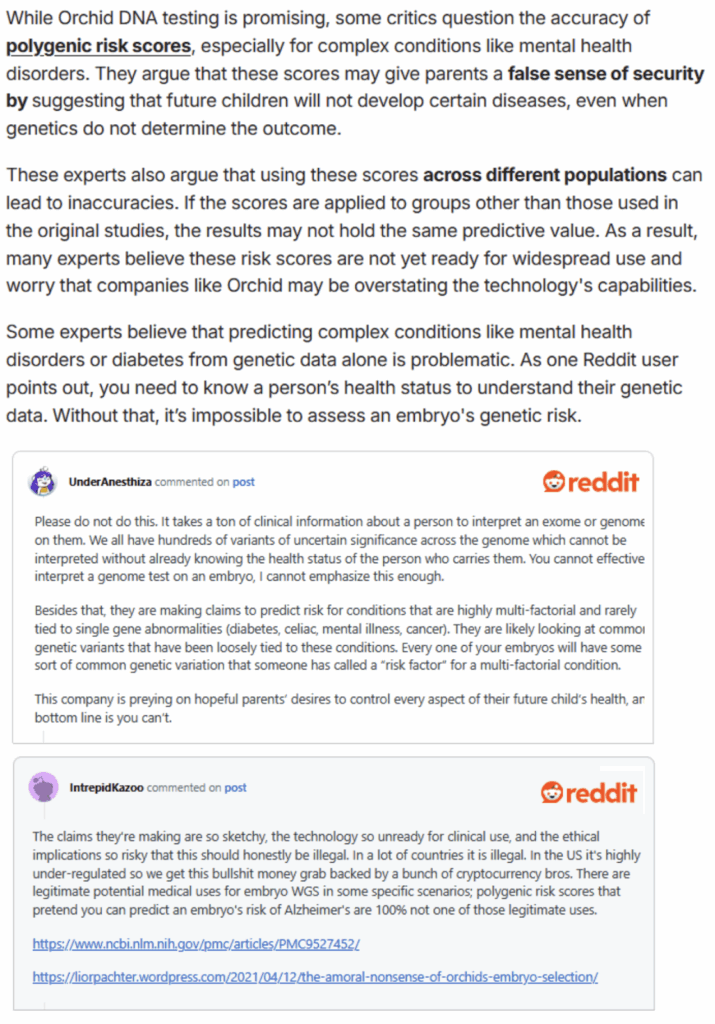
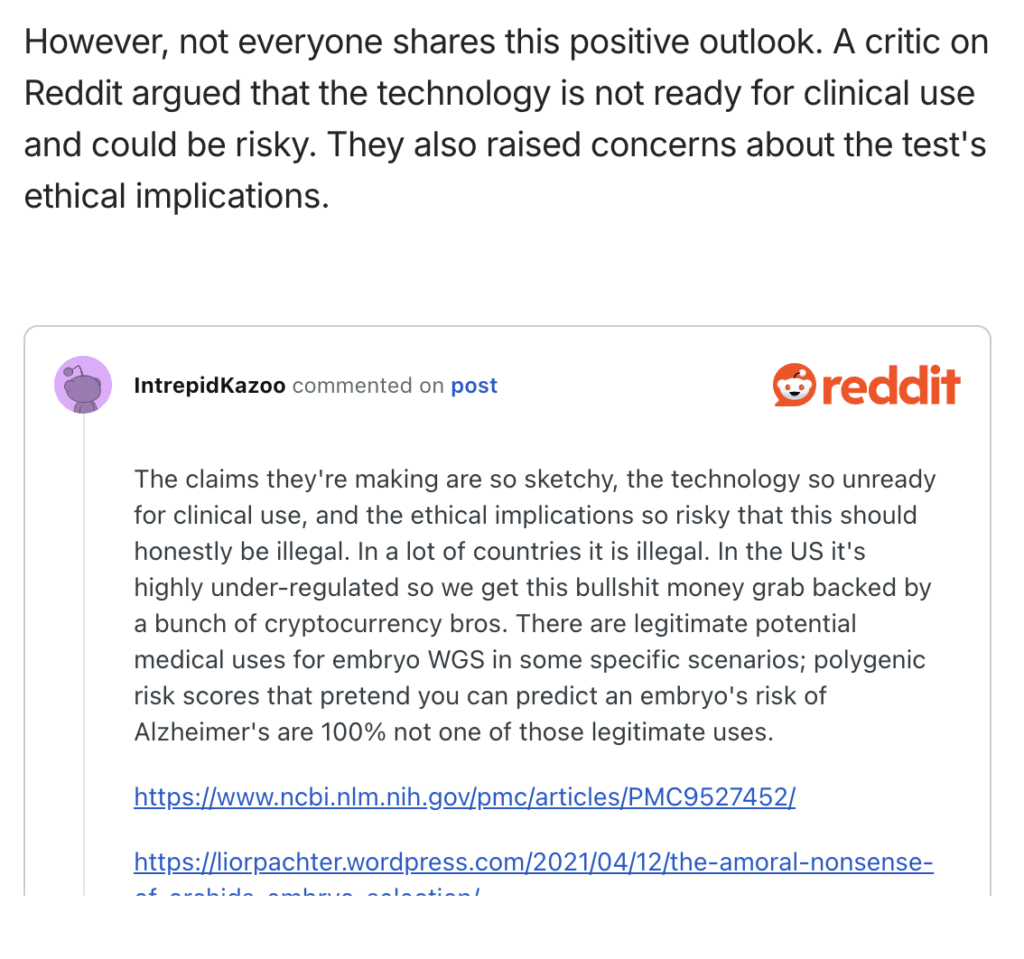
This is obviously absurd given that Nucleus themselves develop and sell polygenic risk scores and clearly indicates that nobody bothered to even skim this post before putting it online. It appears that they’ve updated the post to remove the egregious sections since the page was last archived (which appears to be shortly after Nucleus launched their own IVF product), but it is a curious strategy to push out AI slop criticizing a company’s product on ethical grounds and then immediately pull it after they themselves began offering the product.
Accusations of intellectual property theft from Genomic Prediction
When searching for recent news about Nucleus, I discovered an even more dramatic twist to this story: it seems Genomic Prediction, a competing embryo selection company—and also their business partner—filed a federal lawsuit against Nathan Treff (one of the co-founders of GP, who recently moved to Nucleus), Talia Metzgar, and Nucleus Genomics a few weeks ago, alleging theft of trade secrets and confidential information. Here is the Law.com summary:
According to the suit, Treff [one of the co-founders of GP] deleted data from his company laptop and disabled security cameras before his abrupt resignation in August 2025, while Metzgar emailed 30 confidential documents to her personal account, enabling Nucleus to rapidly expand into embryonic DNA testing using Genomic Prediction’s proprietary methods.
If the claims made are true, they are fairly damning—they suggest that Treff and Metzgar blatantly absconded from GP with proprietary, business-critical data and immediately transplanted that data straight into Nucleus.
To me, however, the most interesting part of such court intrigue is always how the existence of the criminal acts comes to light to begin with. In principle, it’s not terribly difficult to commit a ‘perfect crime;’ being hired away by a competitor is no great sin, and it’s not like every single departing employee is automatically scrutinized for theft of intellectual property. So how, exactly, did they slip up?
Reading the full complaint in Genomic Prediction Inc. v. Treff et al. is quite illuminating. It appears that GP first became aware of their (allegedly) duplicitous actions from … the Nucleus president sending emails to Treff’s old GP email address after his departure.


For those readers taking notes on how to orchestrate your own theft of trade secrets, I would recommend not explicitly antagonizing your previous employer immediately after your departure even as they hire you back as a consultant:

The entire matter is frankly a little baffling to me. It’s obvious that Nucleus and GP are now competitors, and Treff and Metzgar both signed 18-month noncompetes with GP, so what did they expect when they joined Nucleus and immediately launched polygenic scoring for embryos?

Apparently, their solution was to simply claim that Nucleus is not a competitor of GP, which I suspect will prove to be a rather ill-conceived plan.
At this point it seems pretty clear that Nucleus is willing to play a bit loose and fast with consensus reality, but who among us haven’t fabricated a few reviews and churned out AI slop for SEO purposes in pursuit of revenue growth? At least their science is solid, right?
Well, as it turns out…
The entire Nucleus Origin whitepaper is plagiarized
On October 21, 2025, Nucleus announced the release of Nucleus Origin, ostensibly a “a breakthrough in applying AI to genetic analysis.” Specifically, they claim that:
Origin is a family of nine genetic optimization models that predict human longevity from an embryo’s DNA more accurately than any genetic model to date.
Trained and validated on data from millions of individuals, Origin sets new accuracy benchmarks for predicting age-related conditions such as heart disease and cancers across diverse ancestries.
The Origin website links to a medRxiv whitepaper. Let’s take a look.
There is no AI breakthrough
First, it’s immediately obvious that there is absolutely nothing novel about the “AI” used in their paper.

We have known how to construct polygenic risk scores from GWAS data for well over a decade (the first PRS was constructed back in 2007). In fairness, the methods have become somewhat more sophisticated since then. How are they actually computing their PRSs?

Well, it turns out they’re literally just collecting datasets and running SBayesRC, a hierarchical Bayesian model for PRS construction published in 2024. I don’t think taking a method from the academic literature and running it more or less as-is on your dataset constitutes a “breakthrough in applying AI to genetic analysis.” But maybe I just don’t know what qualifies as a “breakthrough” in genetics, so perhaps we can give them the benefit of the doubt for a minute and look closer at the details of their work.
The entire paper is basically a copy of Herasight’s earlier preprint
Upon closer examination, the entirety of the Origin paper seems to be a sloppy near-duplicate of a preprint by Herasight, a competing embryo selection company, that was posted on August 8, 2025. Both papers construct PRSs and validate them within-family and across ancestries in very similar ways. Both papers report the same types of statistics in the same visual formats. Both papers cite the same literature and use the same analytic methodology. It’s just that the Herasight paper was posted 3 months before Nucleus Origin.
First, skim the two abstracts back-to-back. Here’s Origin:

And here’s the Herasight paper:

It’s immediately apparent that the Origin whitepaper follows nearly the exact same logical flow as the Herasight paper, and as we examine each step of their analyses, we see even more striking similarities between the two papers.
Identical polygenic score construction methods
First, both papers construct polygenic scores for a range of diseases. As mentioned previously, Nucleus Origin uses SBayesRC, which is a method previously described in the literature that helps account for linkage disequilibrium and cross-ancestry differences. Unsurprisingly, so does Herasight, and the exact steps of their analysis move almost in lockstep. Nucleus first uses SBayesRC to impute summary statistics, secondly meta-analyzes them with inverse variance weighting, and thirdly uses SBayesRC to directly compute the PRSes:

This methodology is nearly identical. word-for-word, to Herasight’s paper:


Of course, maybe given the state of the field there’s just one best way to perform this calculation and no good reason to deviate from this procedure. However, when you apply a known method in the exact same way that a competing company did several months ago, that simply does not constitute a “breakthrough.”
Also, while this isn’t exactly a smoking gun, the exactly duplicated wording (“Resulting scoring files included weights …”) is certainly suspicious. It suggests that Nucleus started work on their whitepaper by copying over the Herasight paper over wholesale.
Identical comparisons to specific papers in the literature
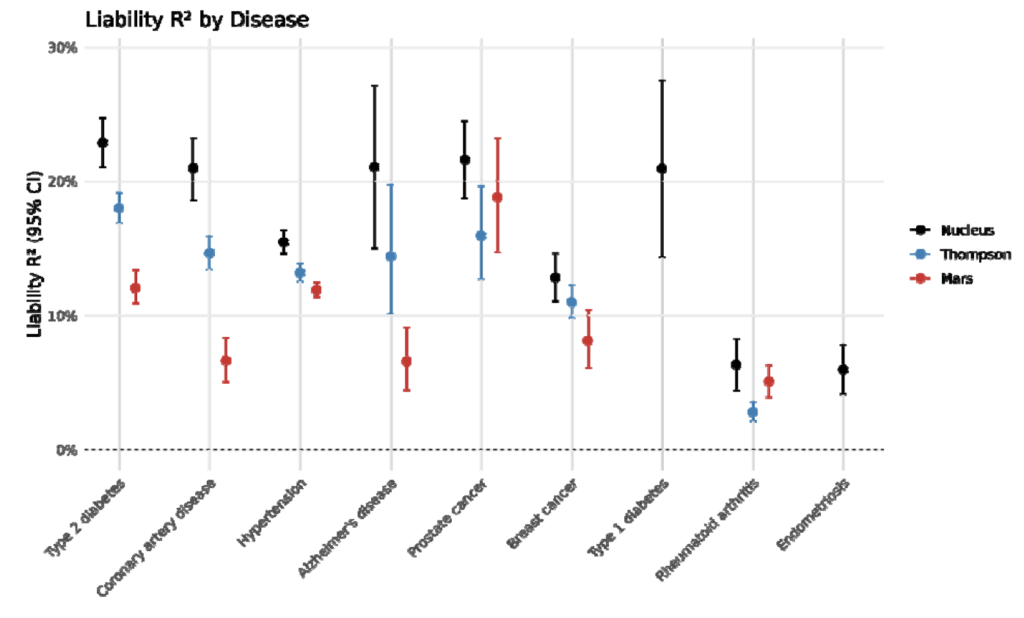
Next, both Nucleus and Herasight compute liability R2 for these diseases and compare their results to the same known literature values (specifically, papers by Thompson and Mars).
Nucleus’s comparison plot:
Herasight’s comparison plot:
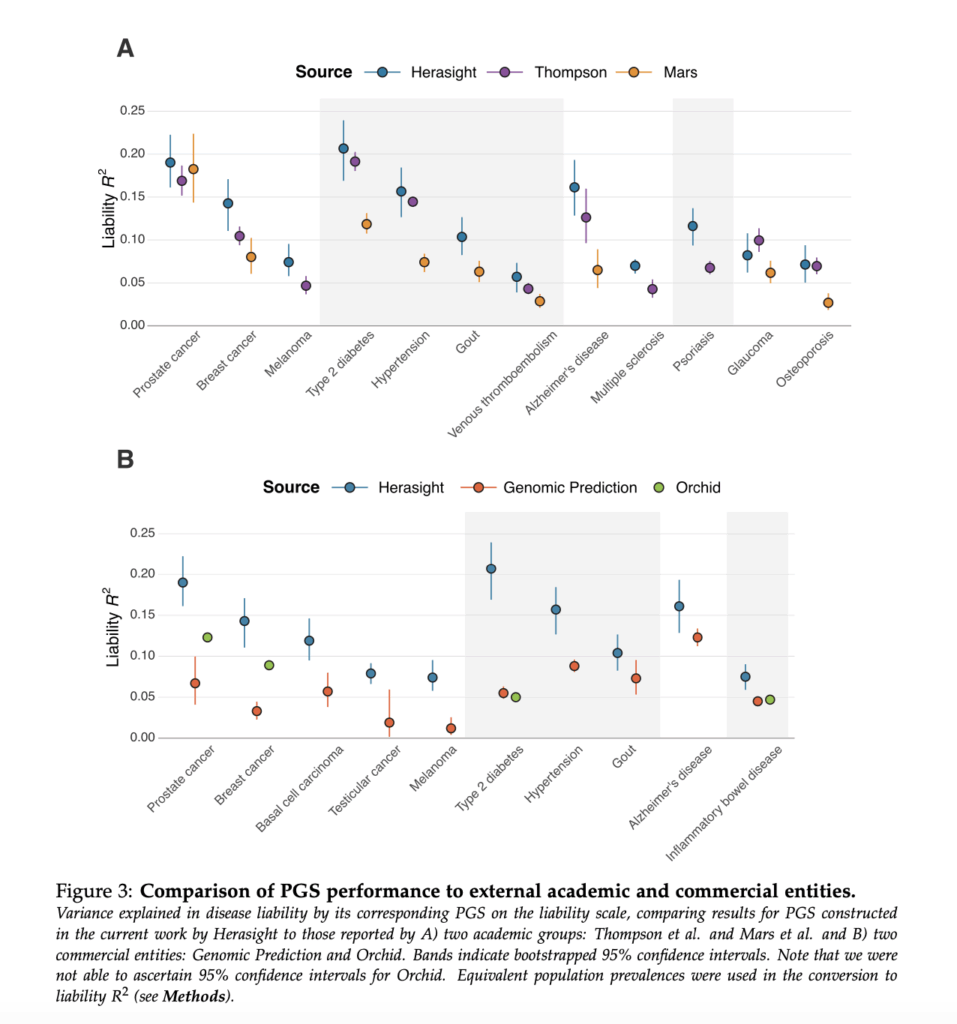
First, Nucleus seems to have copied the exact comparisons and plotting style used by Herasight. Second, the comparisons seem to be copied incorrectly, such as the hypertension results from Mars et al., which from my quick check should come out to be ~7.5%, closer to Herasight’s plotted value from tables S4-S6, not ~11% as Nucleus shows. Third, and most importantly, it is obviously untrue given the existence of the Herasight paper that Nucleus Origin is “state-of-the-art prediction” that “surpasses all published accuracy benchmarks.” Interestingly, Nucleus explicitly chooses not to publish any numbers comparing themselves with competitors, leaving it up to readers to verify their claims.
While we’re on the topic of benchmarking their polygenic scores…

The crucial observation here is that Nucleus has no description whatsoever of how the unreported non-European “lifetime prevalences [are] translated using odds-ratio or hazard-ratio scaling,” making it difficult to understand what numbers they are showing us in Figure 2 exactly—references 40 through 47 are all epidemiological studies describing disease prevalence and have no discussion of how such “translation” might work. This is not just a minor critique; without prevalence harmonization, which Herasight does perform, cross-paper liability R2 comparisons are not meaningful. This is representative of a broader trend in the paper where critical details about methodology, often required for proper interpretation the results they present, are just totally absent.
Nucleus does provide the value for the lifetime prevalence used in the European UKBB validations, but these are exactly the same values Herasight uses and reports in their Supplementary Table 3. While it’s reasonable to adopt similar disease prevalences for such an analysis, especially from the well-curated SEER cancer database, these identical values must be more than a coincidence: according to their preprint, Herasight resorted to using the FinnGen RISTEYS database for hypertension. It appears Nucleus must have done the same.
Identical reference to the same 2025 paper for quality control
Finally, in their respective descriptions of how they processed GWAS data from multiple cohorts as inputs to their polygenic scores, they reference the exact same 2025 paper from Tucker-Drob in the quality control step.
Nucleus’s methodology:

Herasight’s methodology:

One could argue that perhaps Tucker-Drob (2025) is simply the right way to perform this step of the analysis, but after reading through recent GWAS papers that meta-analyze several cohorts together, I almost never saw Tucker-Drob (2025) referenced. This suggests that Nucleus simply copied Herasight’s methods rather than independently coming up with exactly the same way to perform this meta-analysis, which is consistent with them using nearly identical wording (“following [the] recommendations from Tucker-Drob…”).
Any one of the similarities described above could perhaps be excused as a mere coincidence. However, taken in aggregate, it’s pretty clear that the Nucleus paper is not an original work, but instead completely based off the Herasight whitepaper. Their representation of Nucleus Origin as a novel, cutting-edge method is plainly dishonest.
The Nucleus Origin whitepaper is also riddled with errors
Aside from being obviously plagiarized from a paper that they didn’t even deign to cite, the Nucleus Origin whitepaper is also simply poorly written and so full of methodological errors that even an amateur like myself could spot them easily. Let’s go through the most obvious ones.
Potentially overlapping training and test sets
The most egregious problem is that the Origin whitepaper freely slings around terms like “training set,” “test set,” “validation cohort,” etc. without any clear delineation of what is what. In fact, as written, their text seems to imply that they trained on their validation set, meaning that their validation statistics are completely meaningless!
Specifically, they first note that they have a “training cohort consisting of 40,872 siblings” from the UK Biobank:

On the very next page, however, they emphasize the importance of validating polygenic risk scores on a test set with no family overlap with the training set:

But in practically the same breath, they’ve described the construction of their PRS sibling validation set as being directly drawn from the training cohort they described on the previous page! And to make matters worse, because the two halves (in their validation set construction method) contain siblings from the same families, the two estimates of liability R2 obtained on each half are not independent in the typical sense, introducing bias into their inverse-variance-weighted meta-analysis.
Nearly identical cohorts for within-family validation
Related to the above is the possibility that the sibling testing (training?) does not include only siblings but other relationship types as well. For background, a proband is defined as “a person serving as the starting point for the genetic study of a family.” As Herasight’s paper mentions, this includes both people in a sibling pair as well as any offspring of parents also genotyped in the UK Biobank; Herasight uses such probands for within-family validation in the UKB. The citation to Young et al., which develops the relevant within-family methods, shows the available numbers:

How then did Nucleus identify >5,000 more sibling probands than what Young et al. confidently identify across rows 1, 3 and 5 above? The disparity seems too large to be attributable to differences in ancestry filtering that they describe (essentially, keeping individuals who are genetically White British and also self-report the same). My best guess is that they’ve also accidentally classified some parent-offspring pairs as siblings given that these should have the same degree of genetic sharing as siblings (~50%), which is all they seem to filter for in this step.
Even if there was no data processing error, it’s again clear that Nucleus is performing little more than a poor replication of the within-family validation component of Herasight’s work.
Bizarre usage of “total blood pressure”
Hypertension is defined by high blood pressure which in turn is typically defined as high systolic or diastolic blood pressure. Nucleus, however, uses a very bizarre notion of “total blood pressure,” which I cannot find references to anywhere else in the literature.

They also apply an arbitrary offset of 25 to “total blood pressure” to account for hypertension medication usage. It’s not clear where they got any of this from.
This is a particularly weird error because it’s difficult to imagine what generative process could actually result in this kind of mistake. If you naively search something like “definition of hypertension” you’ll get a much more reasonable result. It actually takes more effort to come up with a nonstandard definition of hypertension that nobody else seems to use.
Incorrect ICD9 code used for prostate cancer
Nucleus also lists ICD9 code 714 under their definition of prostate cancer. ICD9 code 714 refers to “rheumatoid arthritis and other inflammatory polyarthropathies,” not to prostate cancer.

Amusingly, they correctly use the same ICD code for rheumatoid arthritis in the following row, meaning that even a cursory pre-publication review of this article would have trivially caught this error (or just ask ChatGPT?).
They also duplicated the rheumatoid arthritis UKB code 131848 for type 1 diabetes and reported UKB’s self-report code 1291 for “mania/bipolar disorder/manic depression” for rheumatoid arthritis and type 1 diabetes:

The charitable interpretation here is that these are just typos and that they did not in fact define cases of prostate cancer as whether they had previously been diagnosed with rheumatoid arthritis, but who knows!
Everything not covered by the whitepaper seems somehow even worse
A history of blatant falsification
In Scott Alexander’s post on the current state of polygenic embryo screening, published a couple months before the Origin whitepaper was released, he discusses various scientific inconsistencies and concerns about Nucleus’s IVF product. Among these concerns, of which there are many, the most egregious one seems to be about how the polygenic scores they offer mostly seem to just be noise.
How do we know this, given that the predictive validity (typically expressed for diseases in the form of a liability R2) is not actually reported by Nucleus? As it turns out, given an individual’s PGS z-score, the disease prevalence, and the reported absolute risk, one can actually back-calculate the implied liability R2, which is a measure of how predictive a PGS is. One can therefore infer the predictive validity that would be needed from a score in order to give the results that they report.
Scott discusses Herasight’s whitepaper, in which they performed an independent validation of the validity of the scores whose provenance they were able to determine (for more details see the original replication, the associated Substack post, various discussions on X) to compare them to the values implied by Nucleus reports:
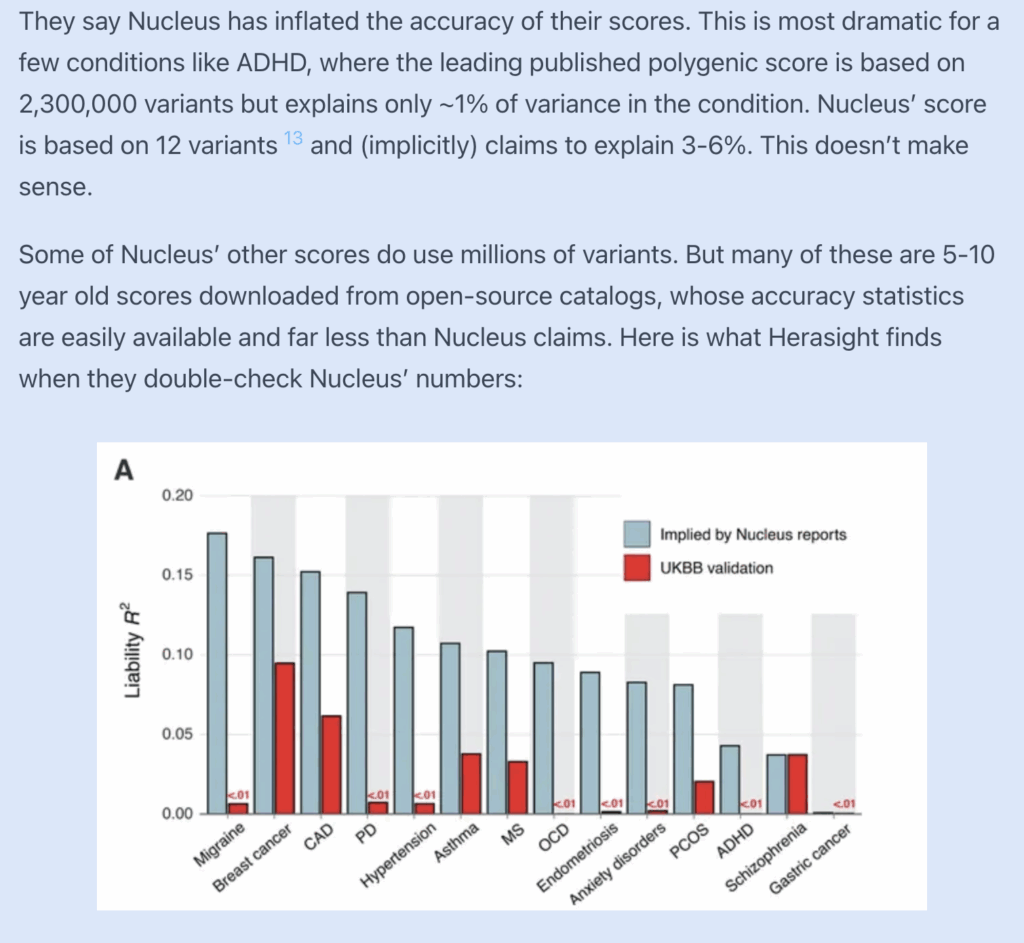
So of the subset of scores that were testable, all but one had substantially lower performance in practice than what would be required for Nucleus to have delivered the reports that they did.
It’s not difficult to see why this might be: for many diseases, the “polygenic” scores Nucleus shipped (ships?) to customers are built from a small handful of GWAS lead SNPs: 6 variants for gastric cancer, 12 for ADHD, 14–21 for PCOS, endometriosis, anxiety, and severe acne, 42 for hypertension, 50 for Parkinson’s. It also seems that a large fraction of these scores appear to be recycled almost verbatim from Nucleus’s open-source ancestor Impute.me (who again seem to have taken them from publicly available academic repositories) and are more than 5 years old.
For anyone who is not familiar with polygenic prediction: these variant counts are extremely suspicious. With very few exceptions, PGS constructed from tens of variants cannot attain clinically meaningful levels of genetic risk prediction (hint: the key term in polygenic risk scores is polygenic). Instead, you would need to use hundreds or thousands of genome-wide genetic variants to approach the state-of-the-art in academic research.
Bad performance would of course simply show up in a validation. However, before basically being forced by their competition to actually conduct one on their nine scores, they seem to have just… pulled their numbers out of thin air?
This might have been partially remedied for the subset of traits described in their Origin whitepaper (?), but even then, that would still only represent a subset of the more than 30 outcomes they claim to offer predictions for on their website. In any case, I myself have difficulty trusting the (unverifiable!) results from a company that is so apparently willing to misrepresent the performance of their scores.
Terms of Service are self-contradictory and highly restrictive
Their Terms of Service are also … interesting … for a company that purportedly offers high quality genetic tests. For example, they say that their carrier screening products are “physician-ordered and reviewed”, but two paragraphs down, that “none of the [Nucleus] Products provide medical diagnosis, treatment or advice, nor are results, reports or analyses reviewed by physicians”. So which is it, exactly? Does or does not a physician review your report?
The dispute resolution rules are also extremely restrictive—you waive your right to go to court for disputes; they must go directly to binding arbitration. Class actions are explicitly barred in a clause; if that clause is deemed unenforceable, then your only recourse is individually suing them in New York court. This might actually come in handy, given that there is actually an ongoing class action investigation against Nucleus (and their competitor Orchid) by consumer protection lawyers at Migliaccio & Rathod. Oh, and if you do have any disputes, you have to start the process within a year, otherwise your claim is “forever barred”. For a company that offers tests on embryos where the outcomes can hardly be known until years after the initial test, it reads like they would very much prefer you not rely on anything it is actually selling.
Again, it’s worth emphasizing that selection of a company that will choose an embryo for your future child is a relationship where trust is absolutely paramount. It’s hard to imagine how I could trust a company that seems to have so little confidence in the reliability of their own products.
Nucleus is a NY-based company, advertising their product in NY, without being allowed to sell it in NY
In the Terms of Service, Nucleus also mentions:
Nucleus does not accept DNA samples that are collected in or returned from the state of New York … DNA samples collected in or returned from the state of New York will not be processed … If a DNA sample is submitted in violation of these restrictions no refund will be issued.
This is probably because New York state—where Nucleus is based out of—has notoriously strict regulatory requirements, particularly for direct-to-consumer genetic tests. In addition to obtaining the standard federally required certifications, labs based in NY have to obtain an additional state-level license to process human specimens, which I suppose they haven’t gotten yet. Which, fair enough, regulation is a PITA, and things take time.
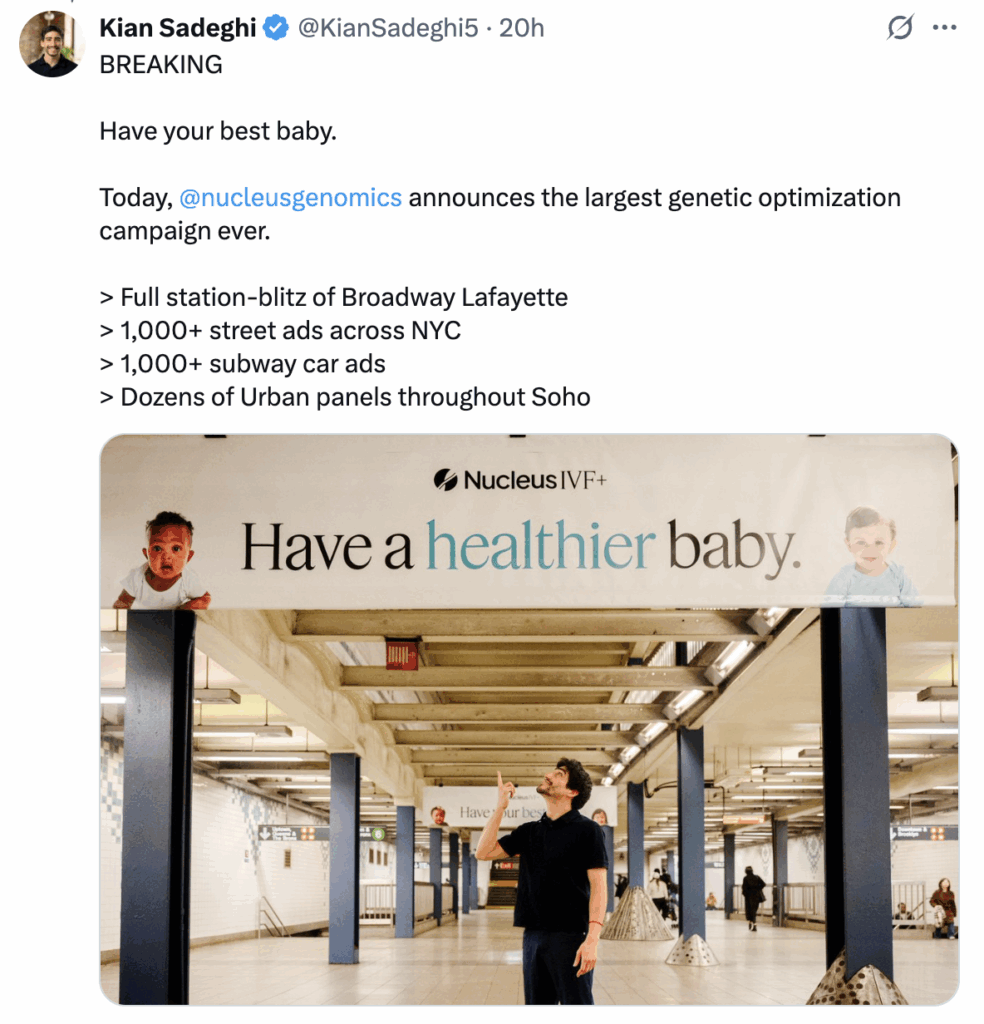
But just a few days ago, Nucleus launched “the largest genetic optimization campaign ever,” basically a giant advertising blitz for their IVF screening product, in none other than New York City itself. It seems reasonable to assume that if you’re a New Yorker viewing an ad for an IVF product in NYC, you would think that Nucleus wants to sell you their IVF product in NYC. But the ToS explicitly bans you, a NY resident, from sending Nucleus, based in NY, your DNA, which is a prerequisite for this IVF test.
Contractually refusing New York samples seems actually understandable under these circumstances. But still, I’m a bit skeptical about an overall business strategy that goes like
- Base the company in New York City.
- Build an IVF funnel that hinges on a parental WGS test.
- Spend millions of dollars saturating New York’s subway system with ads for that test.
- Explicitly forbid New Yorkers from using it.
- ???
- Profit (?)
Concluding thoughts
Ultimately I’m left at a loss for words at the magnitude of the errors in Nucleus’s published work and the overall sense of non-seriousness they exude. Some of the errors and inconsistencies really do range on the absurd, and the vast majority of these problems could have been caught if even a single person actually read through their materials before publication.
Since their inception, Nucleus has marketed itself as using state of the art polygenic scores, yet in practice they have largely relied on old models, many of which were copied directly from their open-source ancestor Impute.me. They did not validate these scores properly or transparently, and their actual predictive performance, when reverse-engineered from their own reports, falls drastically short of their implicit marketing claims, sometimes by an order of magnitude, rendering many of their predictions essentially worthless. When Scott Alexander asked about these discrepancies, Nucleus engaged briefly but then asked him to stop messaging them:

Only after competitors publicly documented these issues and released a detailed whitepaper did Nucleus appear to hurriedly attempt to update their methodology with the release of their “Origin” scores. But Nucleus Origin itself is transparently a poorly executed imitation of their competitor’s earlier preprint. It contains no original ideas, is riddled with basic errors and inconsistencies, and was evidently produced without even minimal internal review.
That being said, you kind of have to respect the chutzpah it takes to poach a founder of a competing company and immediately drain them of the domain-specific IP while claiming that you’re definitely not a competitor, make up reviews of your own product, or duplicate a competitor’s paper and call it your own breakthrough—though I suppose the last point here usually probably doesn’t get noticed for a while because most people don’t actually read whitepapers.
But more seriously, this entire episode reveals something fundamental about Nucleus’s philosophy toward its customers. Their business model seems to hinge on doing only the absolute minimum required to persuade well-meaning laypeople that something sophisticated is happening behind the scenes. They don’t appear concerned with scientific rigor or even basic transparency. If they barely addressed the obvious flaws in their product under substantial external pressure, what are the odds they carefully handle all the parts one cannot easily check—the bioinformatics pipelines, sample handling, etc.?
Having children is one of the most consequential decisions a person can make. I would emphatically not recommend entrusting the future of your children to a company that treats its scientific claims with this level of carelessness.
Leave a Reply